Enhancing AIRAlock with ACRO (Automated Checking of Research Outputs) support, and why it matters where the AI runs
In an earlier post I introduced the AIRAlock, the Aridhia Community App we have been building to support output review prior to and during an airlock request. That post described the deterministic rule engine that classifies each file, with an offline AIRA advisory layer that gives the reviewer an interpretive second read. The reviewer makes the decision and is accountable for it, and the AI never overrides a classification. This post covers two recent developments. The first is support for outputs produced by ACRO, a capability that we natively support in the workspace R and Python environments. The second is the ability for a workspace to bring its own language model to power the advisory layer, including a UK sovereign model, while keeping every inference inside the environment.
Why output checking really matters
A Trusted Research Environment puts considerable effort into controlling who gets in, what data they can see, and how the workspace is configured. All of that protection rests on a final step, which is the check applied to results before they leave. If that check is weak or inconsistent, then the work done everywhere else can be undone at the point of release, and the data leaves with an audit trail that records the approval rather than preventing the disclosure.
In March 2026 there was public reporting concerning de-identified participant data from a large UK research resource that had ended up in online code repositories, added inadvertently by researchers sharing their analysis code rather than through any hack or compromise of the environment. The data custodian was clear that there had been no breach of its systems and no evidence of any participant being identified. The data moved through legitimate, approved researcher activity, which is exactly the path an egress check exists to scrutinise. Strong disclosure control is what stands between de-identified data being shared safely and being shared in a form that could later be picked apart.
Working with ACRO outputs
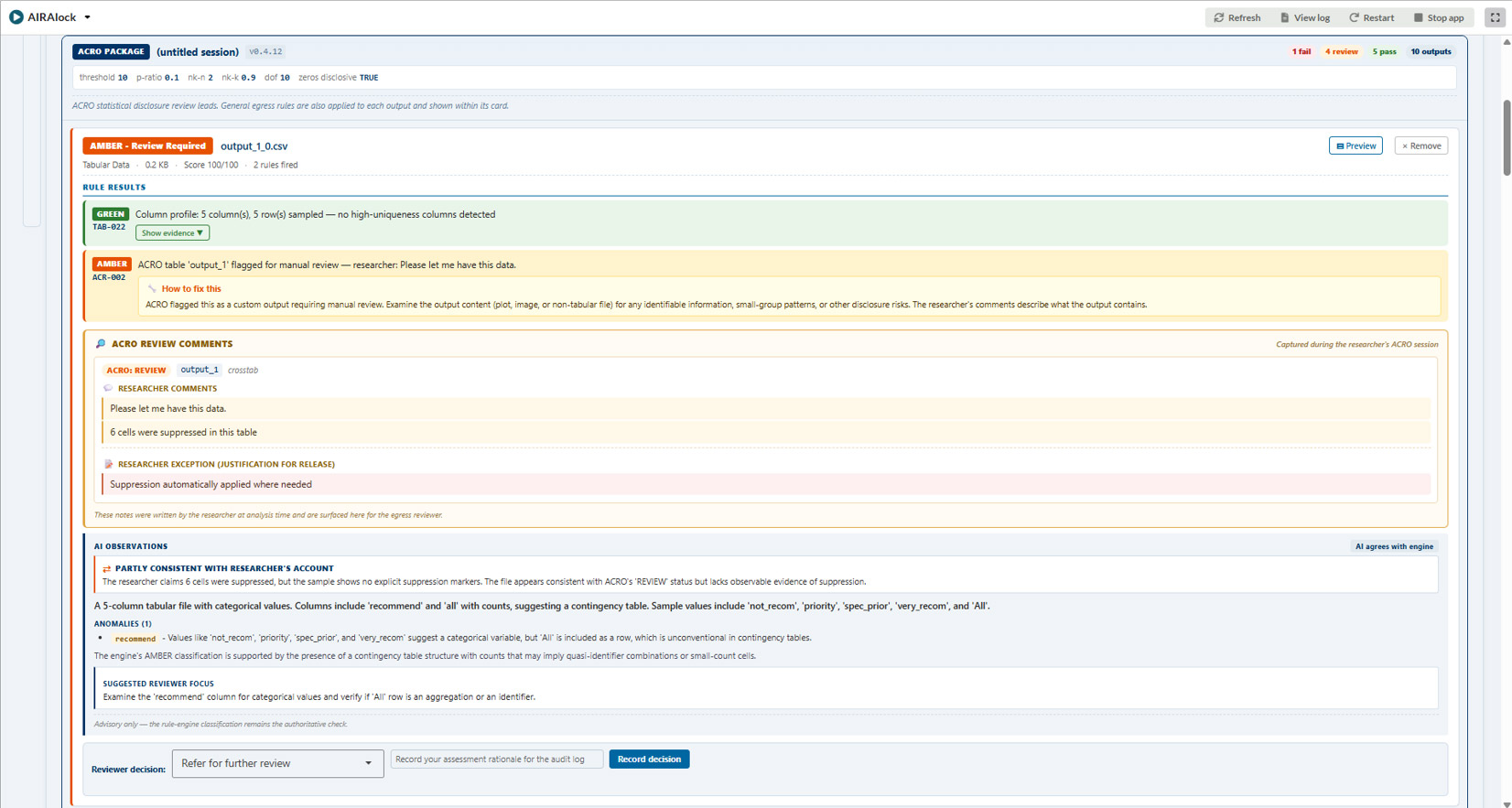
A good deal of disclosure control now happens before a researcher reaches the airlock. ACRO is the tool that implements the SACRO framework, the Semi-Automated Checking of Research Outputs methodology developed under the DARE UK programme. SACRO is the principles-based approach, designed to assist human checkers rather than replace them, and ACRO is the open source package that puts it into practice. Researchers use it at analysis time and it sits over familiar analysis commands, so a researcher writes a cross-tabulation, pivot table, or regression much as they would normally, and ACRO runs formal SDC tests on the result as it is produced. It then records the outcome, any suppression it applied, and the researcher's own comments in a results file that travels alongside the outputs.
ACRO assesses each output as it is produced in code, against the data used, and by design does not set out to assess across multiple outputs, such as differencing between two tables. In the AIRAlock app the whole-package egress review takes place, and a human can be provided information to help come to an accountable release decision. So rather than re-run the per-output tests that ACRO has already done, AIRAlock presents ACRO results and builds on it.
When a researcher has used ACRO, AIRAlock recognises the results file (results.json) and groups the all related files into a single package on the review screen, you can see an example in the screenshot below. The output files are shown as members of an ‘ACRO package’. The package header presents the Statistical Disclosure Control configuration the analysis used, a summary of how many outputs passed, failed, or were marked for review, the researcher's attestation checklist, and any comments the researcher recorded against each output.
Where the AI inference happens
The second development goes to a point that matters more than it first appears, which is where the model actually runs.
A great deal of AI assistance available today depends on sending your text to an external provider. The protections and controls that define a TRE depend on sensitive data staying within a controlled boundary. A model that processes that data by sending it to an external API call has taken the data outside the boundary, whatever the provider's assurances, and the controlled environment no longer controls it. An example of this can be seen recently, with the controversial release of Fable, where Anthropic retains history of prompts and inferences for 30 days regardless of previous enterprise agreements. The same concern that applies to a researcher inadvertently sharing data through a code repository applies to an AI service quietly shipping it to a third party for inference.
This is why the AI in AIRAlock runs through AIRA, the Aridhia AI service that operates inside the workspace boundary as an offline capability rather than a call to an external service. The structural samples the advisory layer reads never leave the scope of the DRE. The reviewer gets an interpretive second read, and the data it was derived from stays exactly where the data access agreement says it should.
The case for sovereign AI
Because AIRA runs the model inside the environment, the workspace is not tied to a single fixed model. A workspace can bring its own model to power the advisory layer through the AIRA framework and run it locally, with no external inference. That choice now includes sovereign options. An example of one such is the recently released Lizzy 7B from Flower.ai, an open-weight SOTA LLM built entirely in the United Kingdom and designed for deployment in controlled, local environments. With ‘bring your own model’ support an UK organisation can run its output-review assistance on a UK-built model, on its own infrastructure, with both the data and the inference staying inside the environment. Again, recently with Fable, it has been shown how easily access to a model hosted outside of a controlled environment can be pulled.
Running a sovereign model inside the workspace means the interpretive help a reviewer reads is produced by a model the organisation has chosen and can account for, trained and evaluated in a known jurisdiction, running where the organisation can see it. It removes the dependency on a remote service whose behaviour, updates, and data handling sit outside the environment and outside the organisation's control. For UK health data in particular, the ability to keep the data, the compute, and the model all within national and organisational boundaries is a meaningful step, and one the wider move toward UK sovereign AI infrastructure is now making practical.
The role of AI in AIRAlock is deliberately restricted to a second pair of eyes that helps the first reviewer interpret what the rules and ACRO have found (if it has been used). The human is always accountable for the final decision. Keeping that role bounded is what lets us take advantage of modern language-model capability without giving up the audit properties that make a TRE governable. Being able to run that model inside the environment, and to choose a sovereign model to do it, means the advisory layer fits the same governance posture as everything else in the workspace. The protections only matter if they hold all the way to the point of release, and that is the point AIRAlock is built to support.
If you operate a DRE and want to discuss how AIRAlock could fit into your egress process, or if you are evaluating the DRE for the first time, get in touch.evaluating the DRE for the first time, get in touch.